
I watched the lecture on Deep Reinforcement Learning and these are the highlights of the lecture.
Video: https://youtu.be/zR11FLZ-O9M
Slides: https://www.dropbox.com/s/wekmlv45omd266o/deep_rl_intro.pdf?dl=0
Website: https://deeplearning.mit.edu/
GitHub Tutorials: https://github.com/lexfridman/mit-deep-learning


Every type of machine learning is supervised learning. The difference is the source of the supervision.
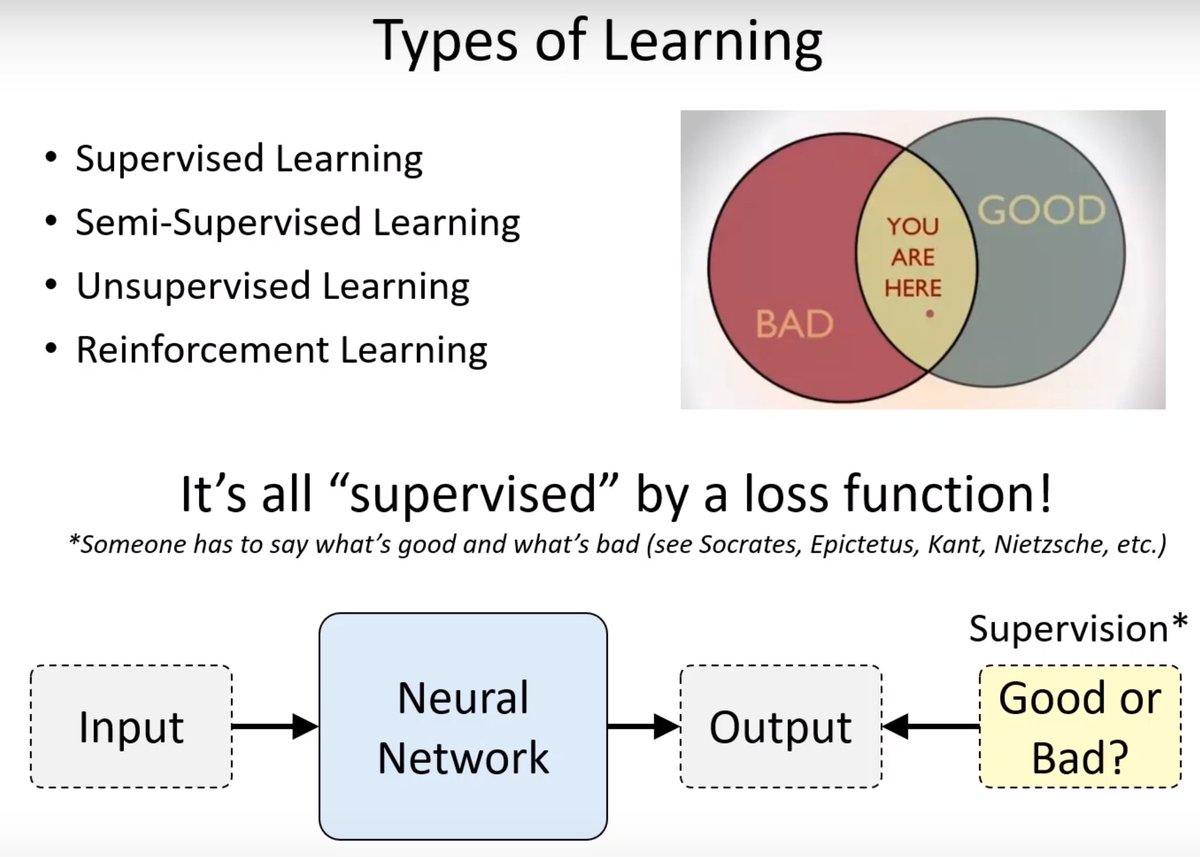
Supervised learning vs. reinforcement learning
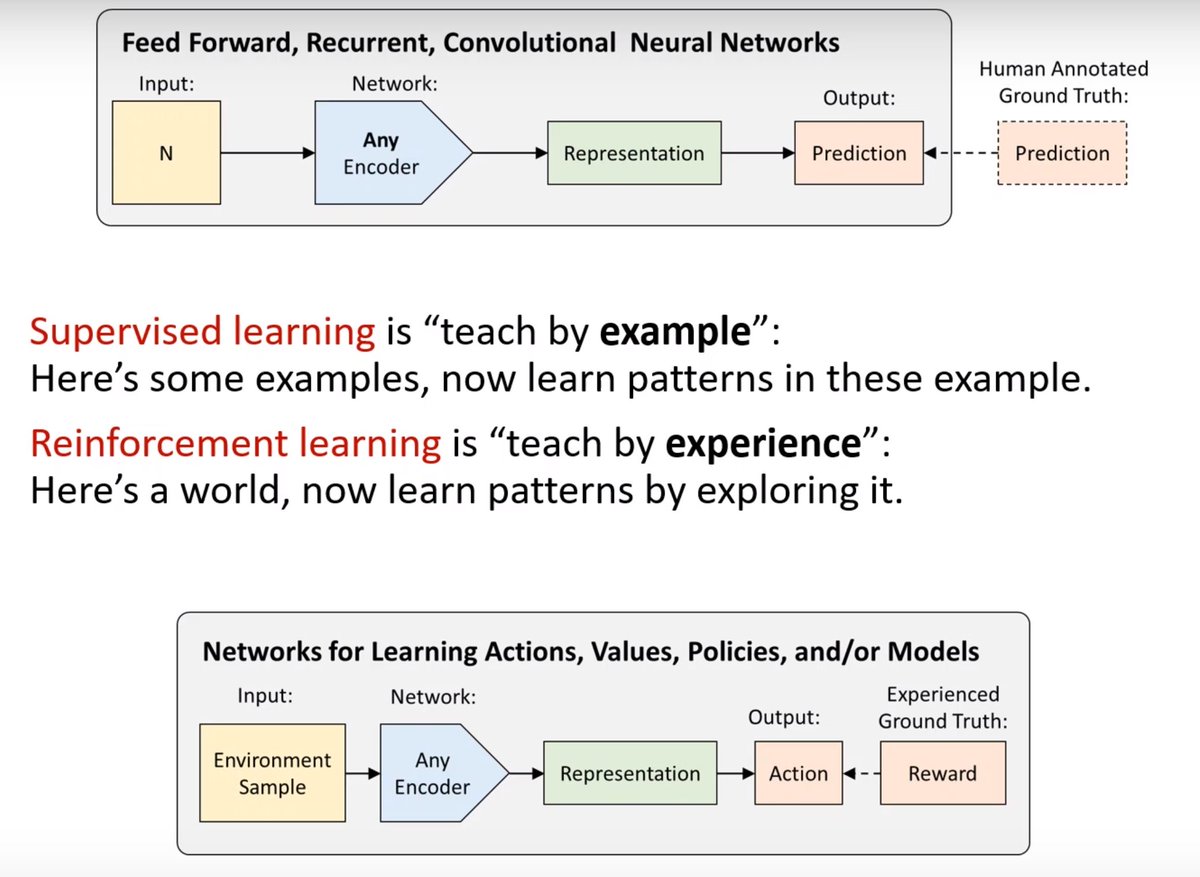
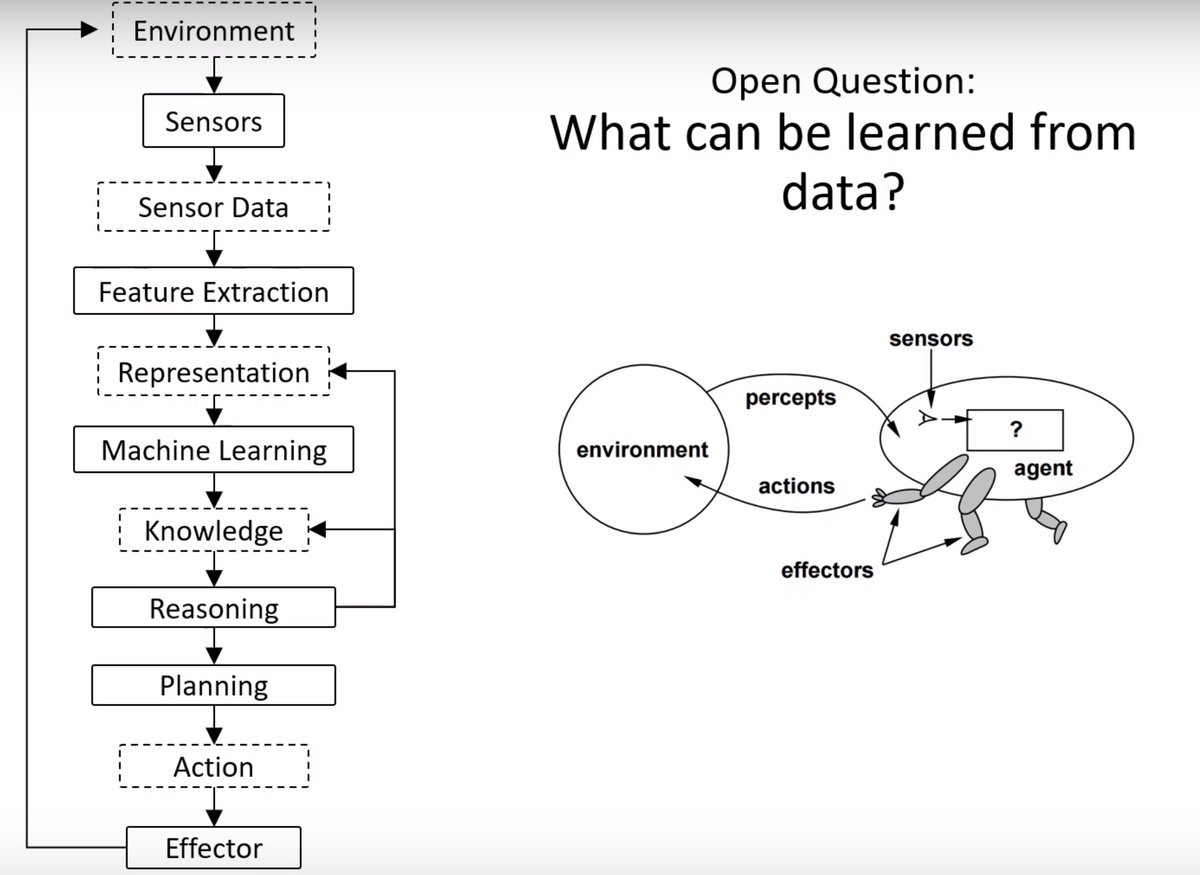
The process of how machines learn to act in the world.
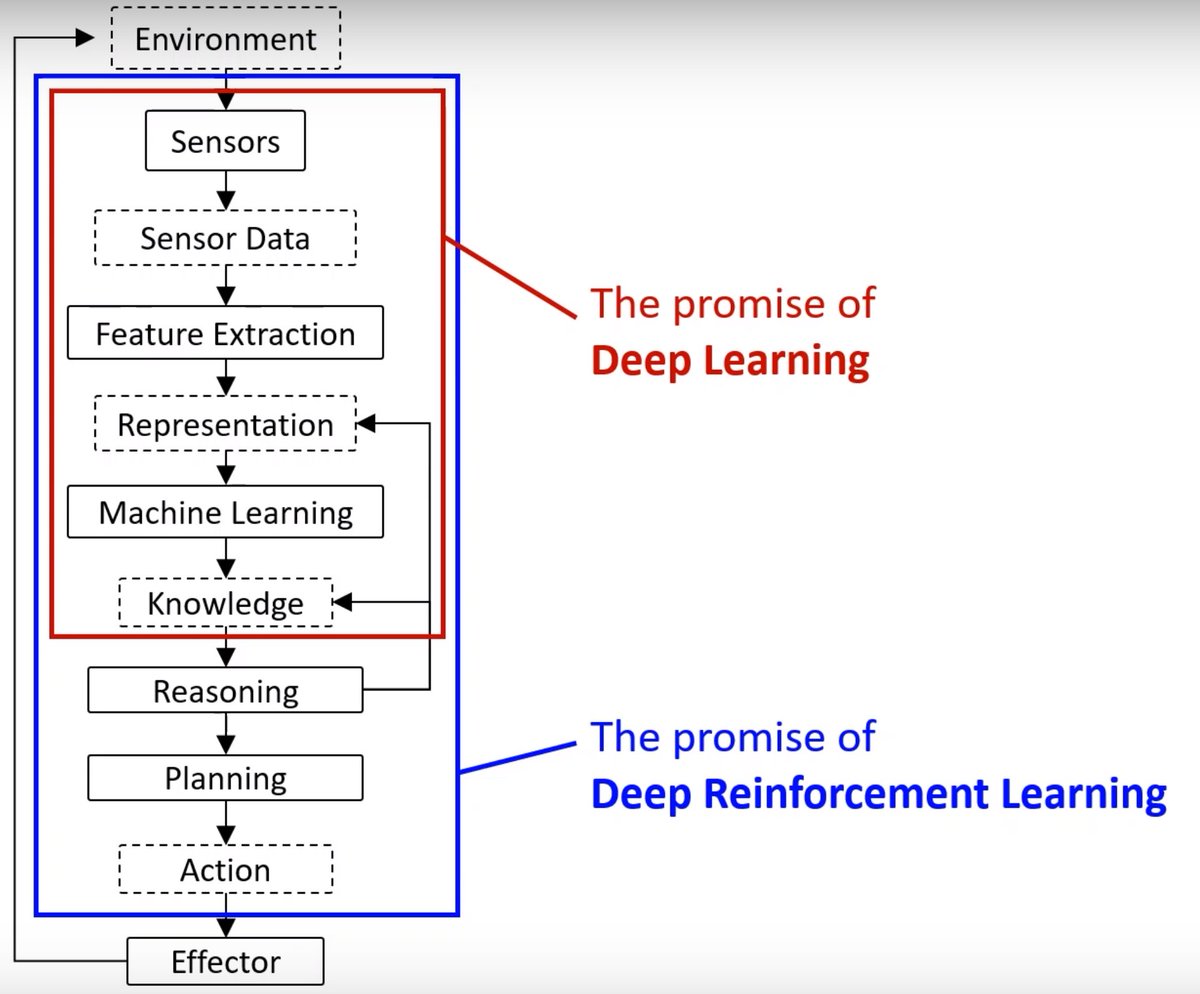
The promise of Deep Reinforcement Learning is building an agent that uses the representation and acts to achieve success in the world.
I instantly lose my focus and concentration as soon as I see cats in the presentation. 😂
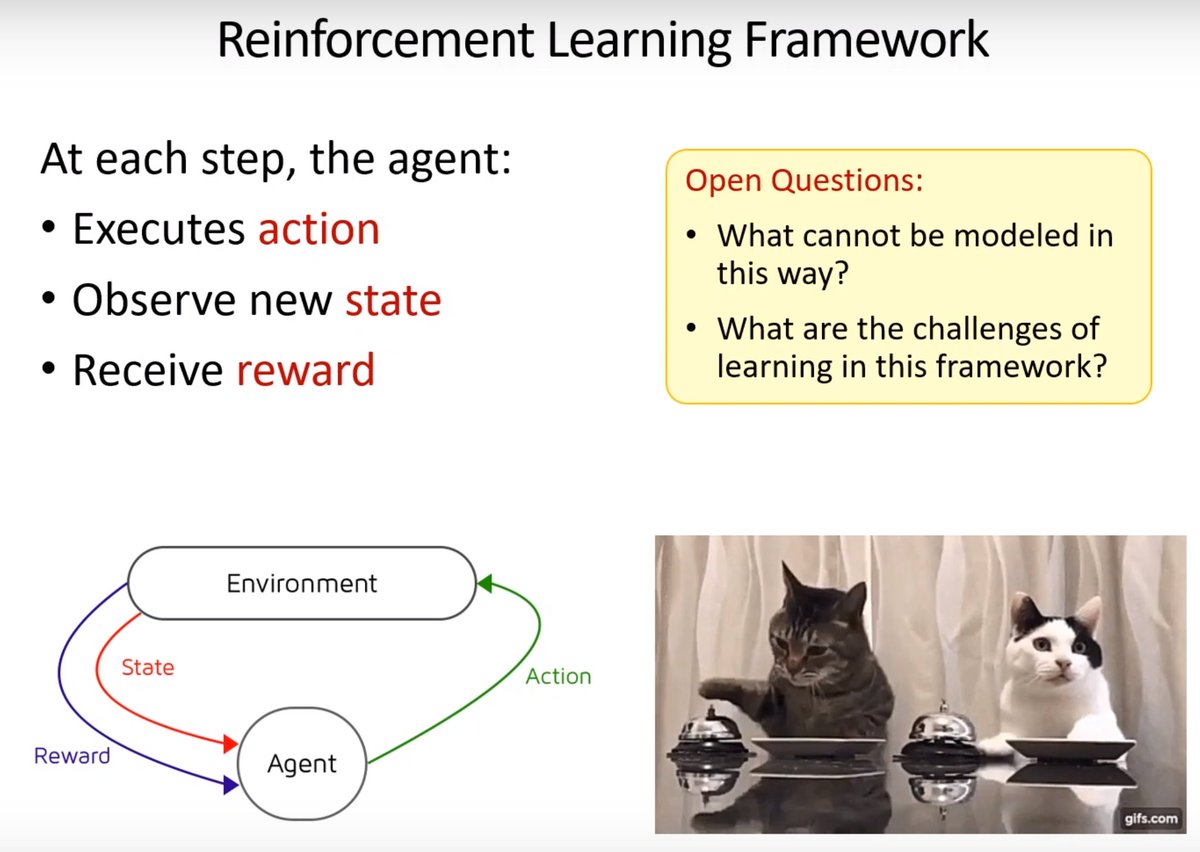
The challenges for Reinforcement Learning in real-world applications.

Interesting. Human life as an example of Reinforcement Learning.

Value-based agents learn how good it is to be in the state and use that information to pick the best one.
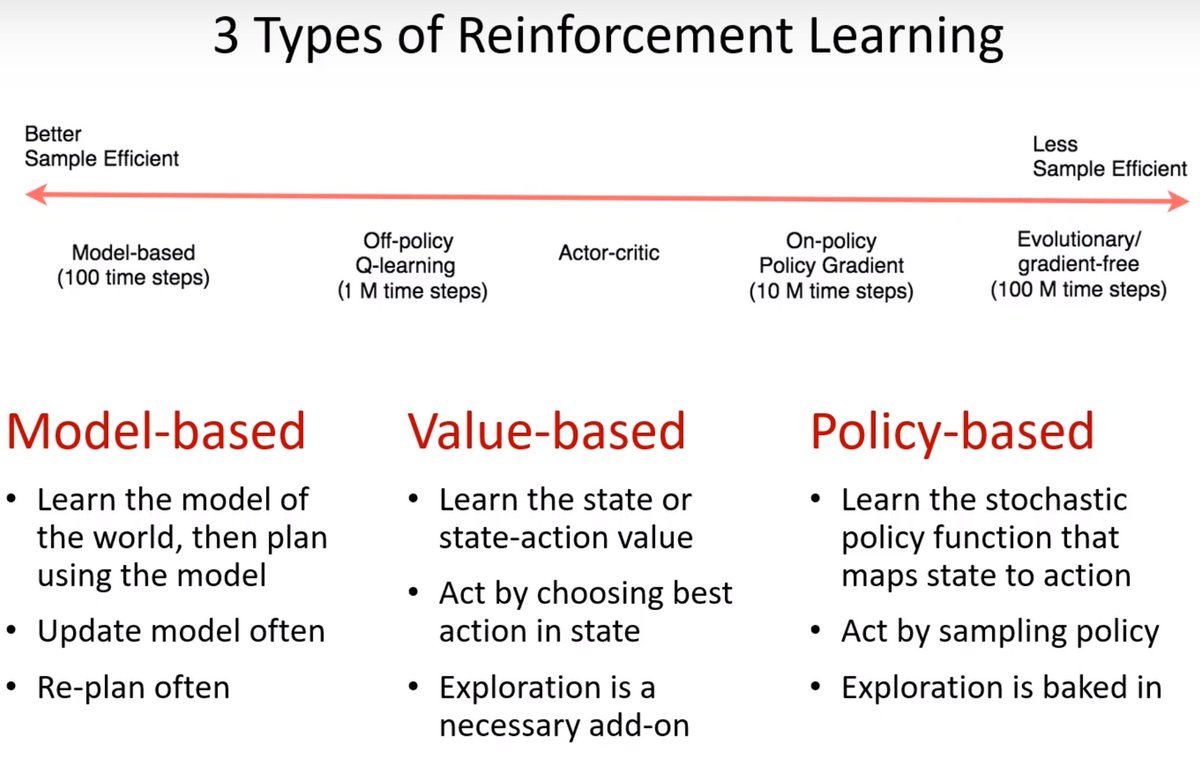
Deep Reinforcement Learning is Reinforcement Learning + Neural Networks where the neural network is tasked with taking the value-based methods and learning an approximator for the function from state and action to value.
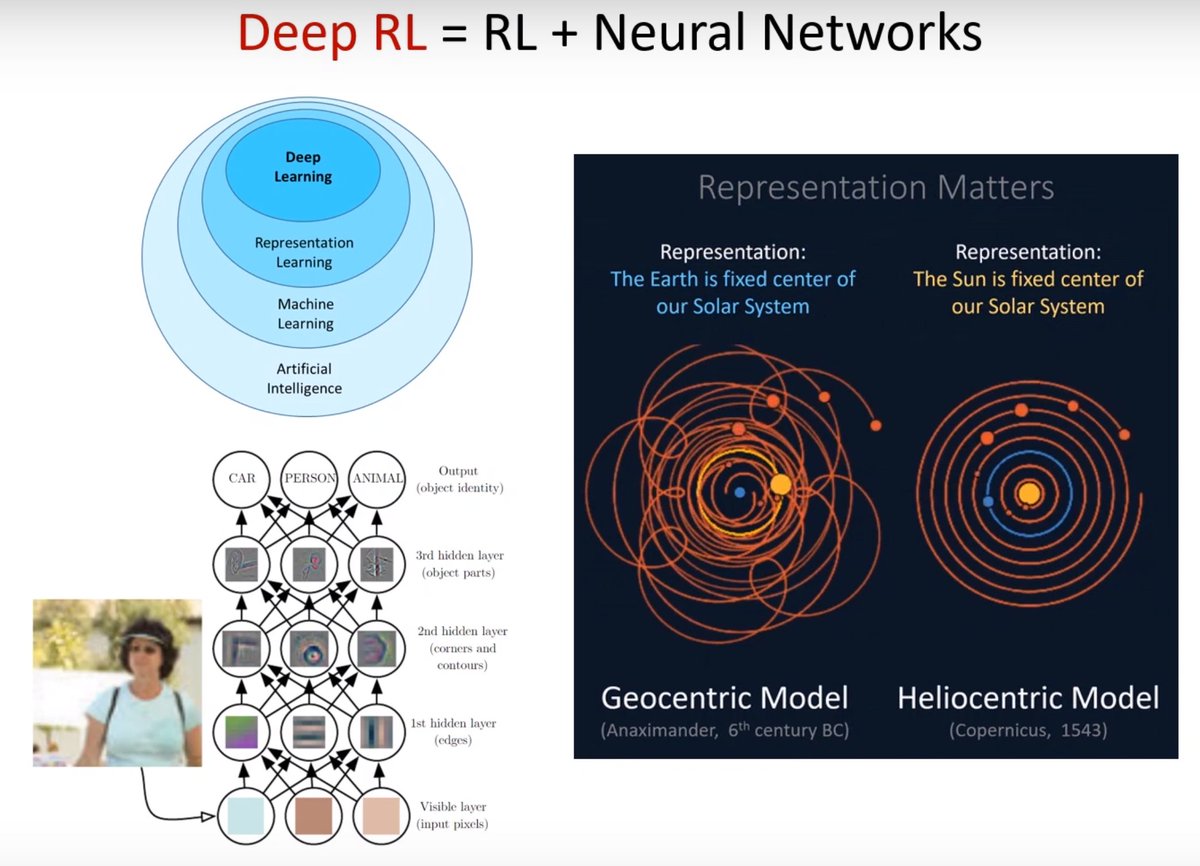
“From raw sensory information neural networks are able to learn to act in a way that supersedes humans in terms of creativity and actual raw performance. Games of simple form is the cleanest way to demonstrate that.”
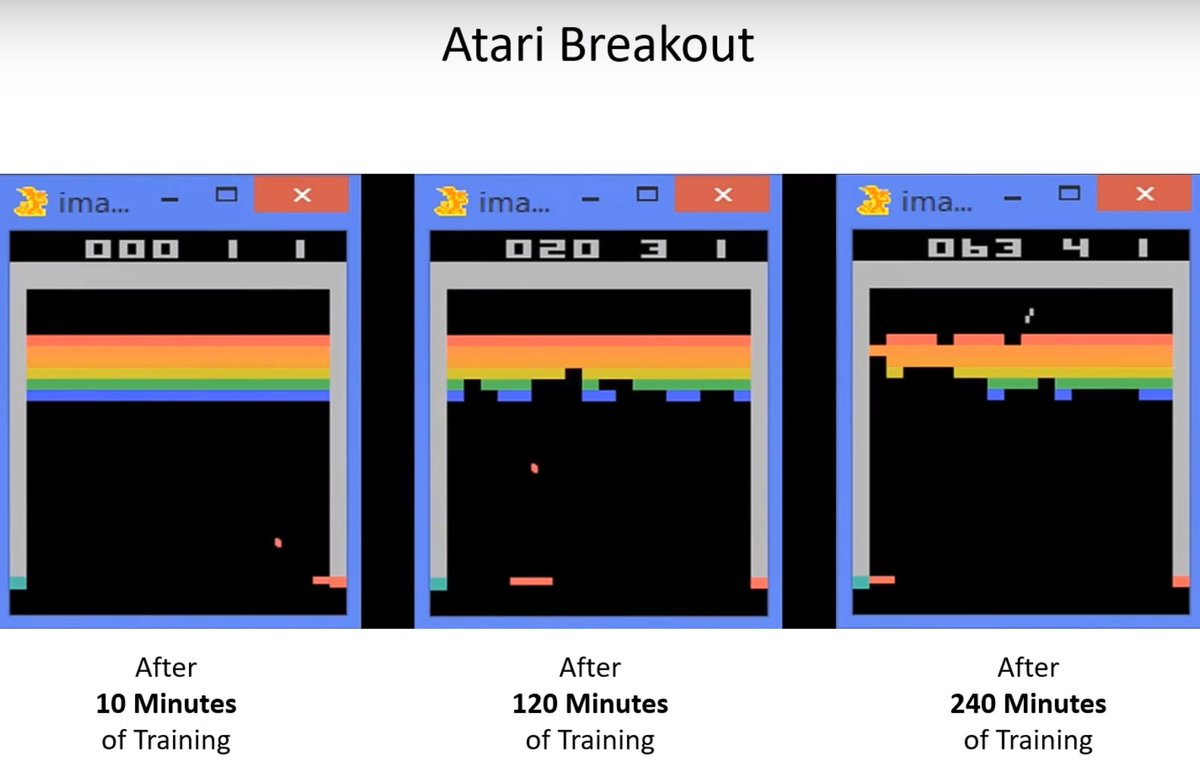
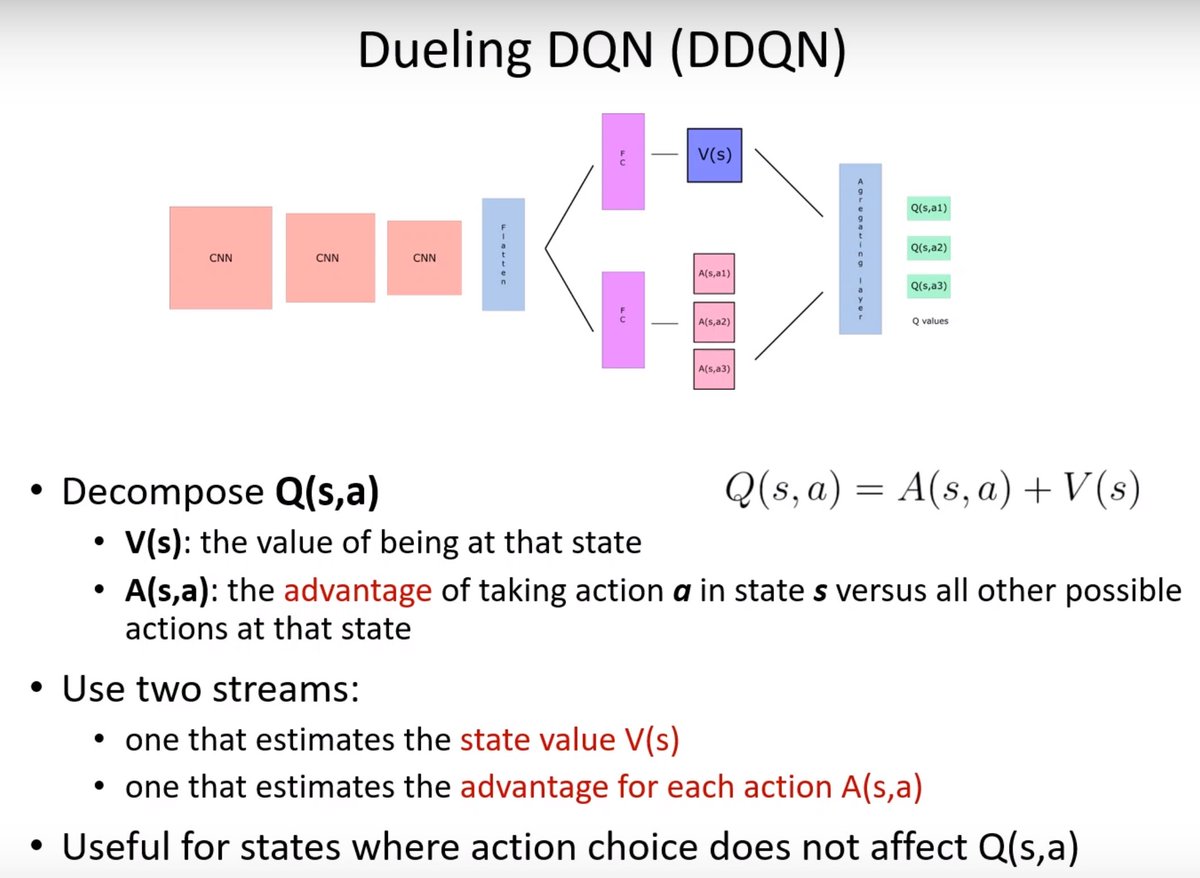
In terms of optimization, DDQN is a better measure for choosing actions. With two streams of neural networks, one estimates the value and the other the advantage.
Policy gradient is directly optimizing the policy. Reward is collected at the very end, every action is punished or rewarded depending if it led to victory or defeat. Everything that was done along the way is averaged out which is why policy-gradient methods are inefficient.

A2C is combining the best of value-based methods and policy-based methods by having an actor that is policy-based and a value-based critic that measures how good the actions are.

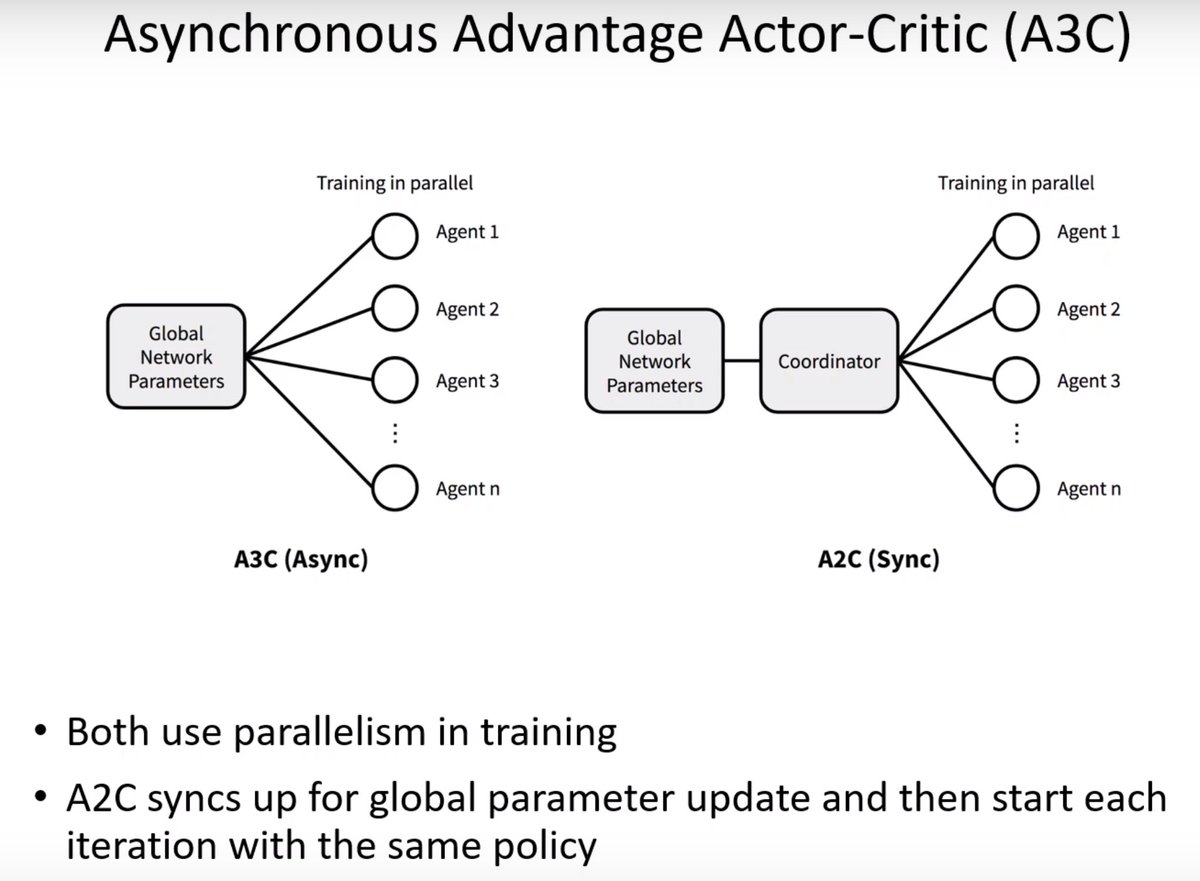
With A3C every agent is updating the original network asynchronously so they are operating on outdated versions of that network. The A2C approach fixes this: Coordinator waits for everyone to finish to update the global network and distributes the same parameters to all agents.
Reinforcement Learning is purely an optimization problem. The actions taken influence the rest of the optimization process so avoid taking bad actions that can lead to the training performance collapsing.

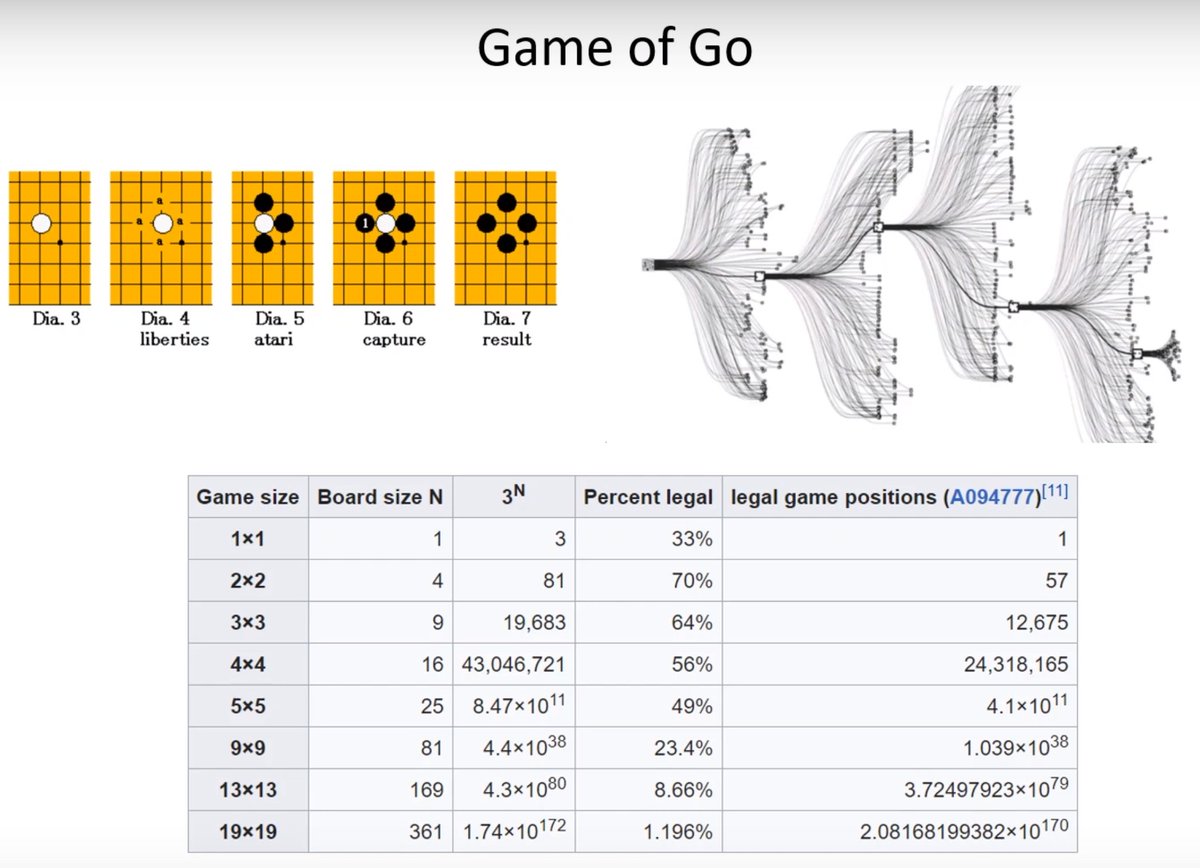
The game tree grows exponentially with turn-based games. In Go it is the hugest of all. The task of the neural networks is to learn the quality of the board, which game positions are most useful to explore and might result in a highly successful state.
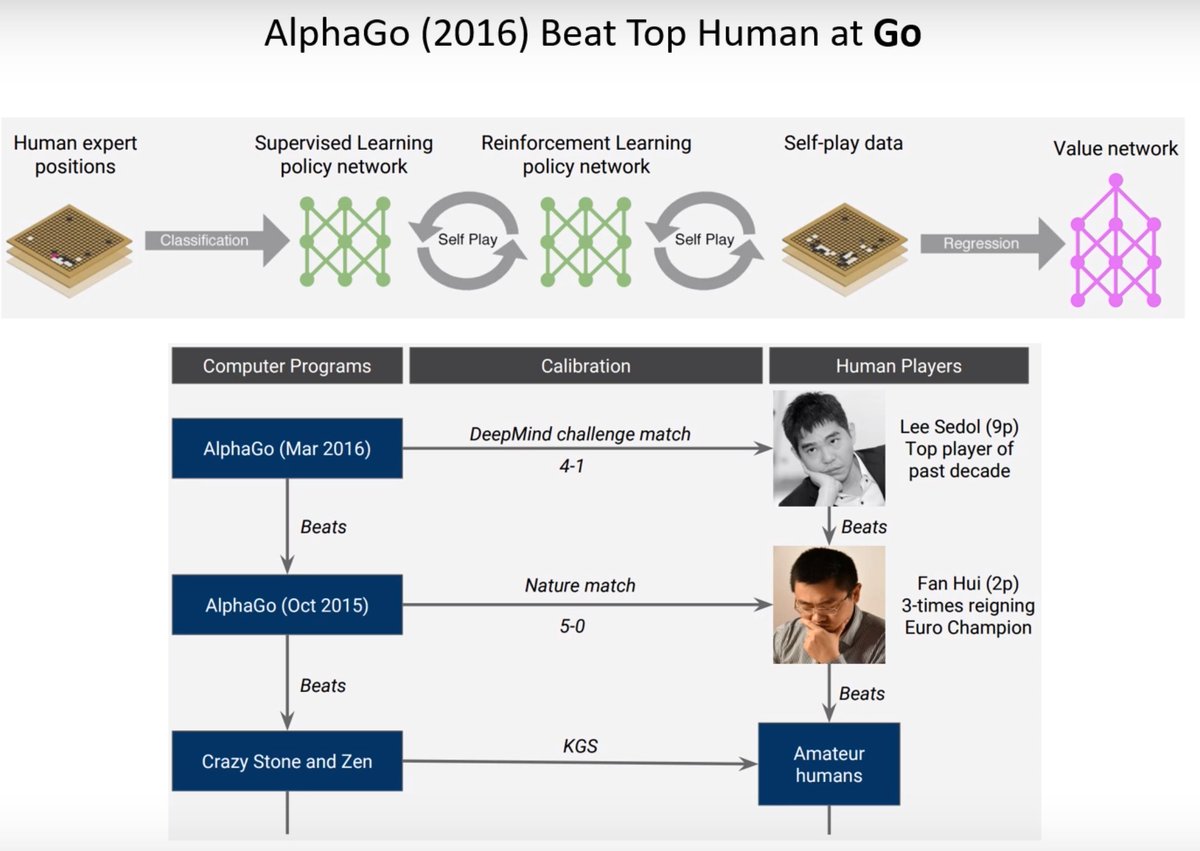
These model-based approaches are extremely sample efficient and they can be exceptionally powerful. These engines are far superior to humans. Based on neural networks you explore certain positions and part of the tree, human grand masters in chess seem to explore very few moves.
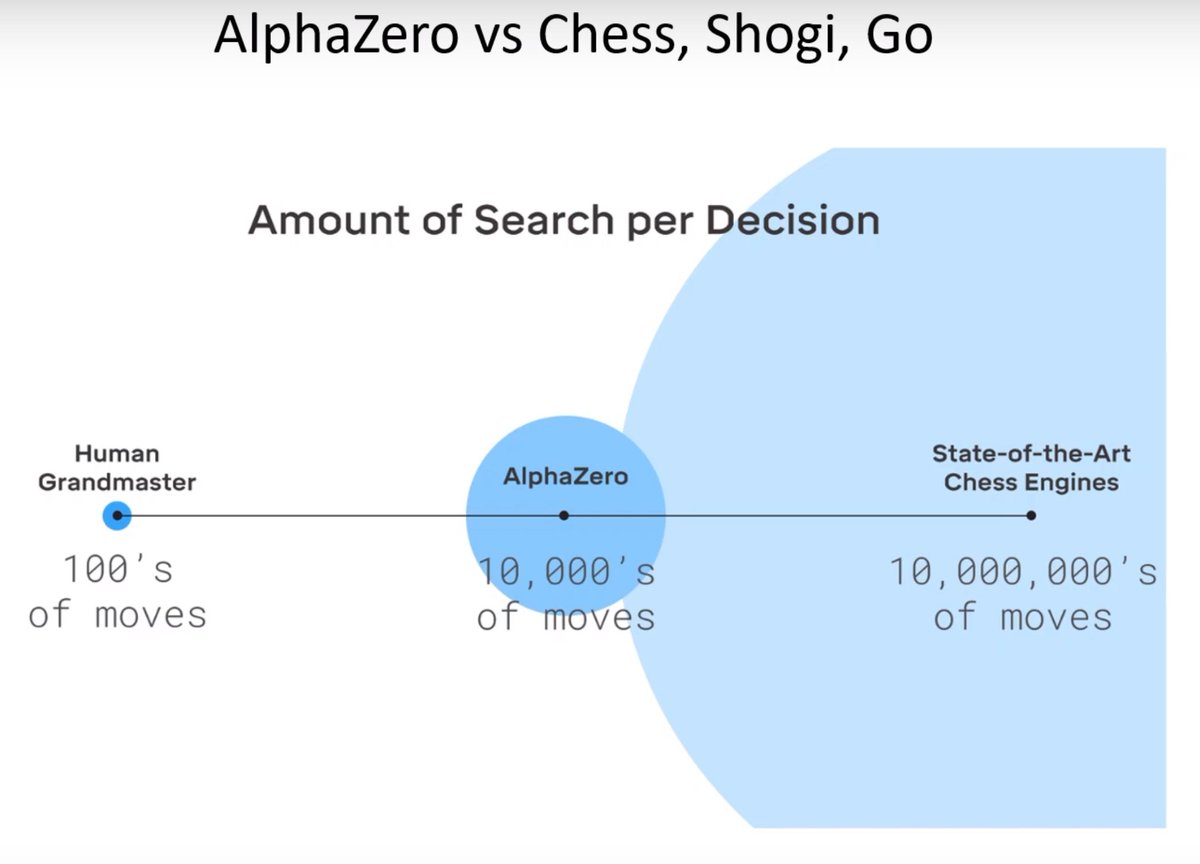
The majority of real-world applications of agents are for the most part have no Reinforcement Learning involved. The action is not learned. This is true for most or all autonomous car companies operating today and robotics.

This is beginning to change. (Can that guy please stop hitting the poor robot animal? 😢)

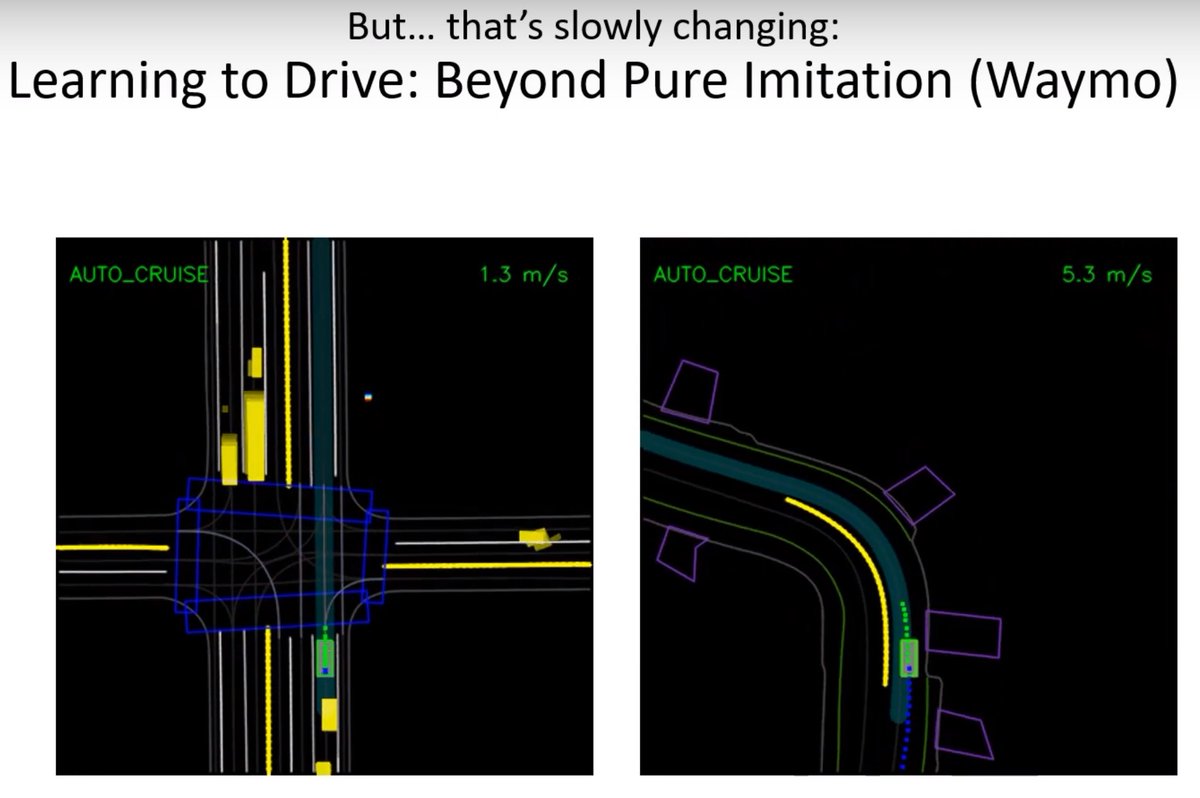
Learn by doing is the best advice. 🙂

